-
Finance - 1finance 2020. 12. 15. 14:25
한창 주식 관련 페이지를 만드려고 하다가 다른 일이 생겨서 한참 미뤄놨던 일..
원래 간단한 필터 정도 구현하려 했는데 종목 정보를 가지고 점수를 내는.. 그런 일이 돼버렸다..
그래서 가져온건 일단
https://finance.naver.com/sise/sise_market_sum.nhn?sosok=0
시가총액 : 네이버 금융
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
코스피 전체 종목을 가져와서
https://finance.naver.com/item/main.nhn?code=005930
삼성전자 - 네이버 금융 : 네이버 금융
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
종목별 상세정보 페이지에
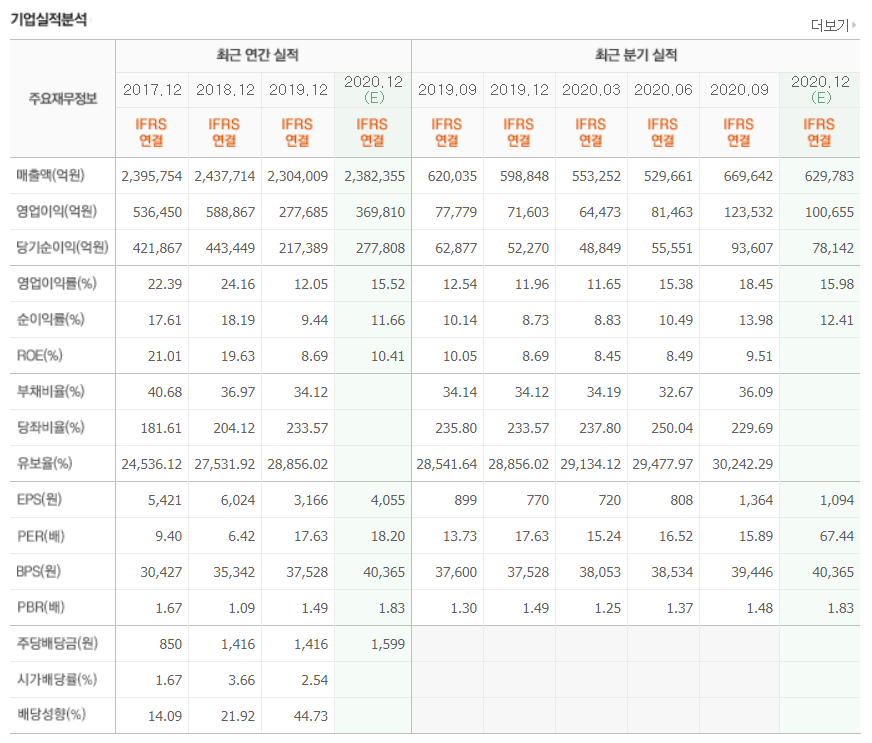
네이버 금융 이 표가 있는 종목들만 추렸다. 그랬더니 1500개 가량 종목중 760개 가량이 나왔다.
그래서 위 표를 그냥 숫자 하나하나 추가한 리스트로 만들어서 학습을 시킬예정이었다.
근데 딥러닝같은.. 자세히는 모르지만 그정도 까지는 필요 없고, 일단 단순 수치로 분석할 예정이니 Lasso Regression 이란걸 알게돼서 사용하게 됐다.
https://zimkjh.github.io/ml/Lasso-Regression
공부하며 기록한 Lasso Regression
디자인팀 과제로
zimkjh.github.io
위에 블로그 참고했다.
일단은 import
# load library import numpy as np from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt %matplotlib inline import warnings warnings.filterwarnings("ignore", category=DeprecationWarning) from sklearn.linear_model import LinearRegression그리고 저장해 놨던 db불러오기
import sqlite3 import pandas as pd # Create your connection. cnx = sqlite3.connect(r'C:\Users\an\Desktop\gitgit\finance\new_page\flask_app\dataFrameNameAndCode.db') cur = cnx.cursor() query = "SELECT name FROM dataFrameNameAndCode" name = cur.execute(query) names = name.fetchall() names cur.close() # df = pd.read_sql_query("SELECT * FROM Name", cnx) result=[] cnx = sqlite3.connect(r'C:\Users\an\Desktop\gitgit\finance\new_page\flask_app\dataFrame.db') #names 에 다 들어감 for i in range(len(names)): df = pd.read_sql_query("SELECT * FROM " + names[i][0], cnx) result.append(df) #이제 dataframe to list real=[] for i in range(len(result)): #0~760 row=[] for j in range(len(result[i])): #0~15 매출액, 영업이익,,,... row = row + list(result[i].iloc[j].values[1:11]) #1~10이 값들 real.append(row)real 이라는 list에 저 위에 표를 그냥 통째로 넣어줬다. 그리고.. 점수의 지표는 전문 증권 어플에서 가져왔다.
for i in range(23): for j in range(len(real[i])): if(real[i][j] == '' or real[i][j]=='-'): real[i][j] = '-0' #names_temp = np.asarray(names[0:23], dtype='float64') answer_temp = np.asarray(answer[0:23], dtype='float64') real_temp = np.asarray(real[0:23], dtype='float64') for i in range(len(real_temp)): for j in range(len(real_temp[i])): if(real_temp[i][j] == '' or real_temp[i][j] == '-'): real_temp[i][j] = '-0'약간의 전처리를 해준건데 여기서 성능향상의 가능성이 있다. 위 표에서 빠져있는 값들에 0을 넣어준건데 여기를 뭐 평균값을 넣어준다거나 아니면 모든 항목에 존재한 값으로만 계산한다거나 그렇게 하면 결과가 좋아질 수 있을 것 같다..
from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.metrics import r2_score,mean_absolute_error, mean_squared_error import numpy as np ridge_alpha = 1 lasso_alpha = 0.1 linear = LinearRegression() ridge = Ridge(alpha = ridge_alpha) lasso = Lasso(alpha = lasso_alpha) linear.fit(real_temp, answer_temp) ridge.fit(real_temp, answer_temp) lasso.fit(real_temp, answer_temp) linear_y_hat = linear.predict(X_test) ridge_y_hat = ridge.predict(X_test) lasso_y_hat = lasso.predict(X_test) linear_r2, ridge_r2, lasso_r2 = r2_score(y_test,linear_y_hat), r2_score(y_test,ridge_y_hat), r2_score(y_test,lasso_y_hat) linear_MSE, ridge_MSE, lasso_MSE = mean_squared_error(y_test,linear_y_hat), mean_squared_error(y_test,ridge_y_hat), mean_squared_error(y_test,lasso_y_hat) linear_MAE, ridge_MAE, lasso_MAE = mean_absolute_error(y_test,linear_y_hat), mean_absolute_error(y_test,ridge_y_hat), mean_absolute_error(y_test,lasso_y_hat) print('R2 score - Linear: %.2f, Ridge: %.2f, Lasso: %.2f' %(linear_r2, ridge_r2, lasso_r2)) print('MSE - Linear: %.2f, Ridge: %.2f, Lasso: %.2f' %(linear_MSE, ridge_MSE, lasso_MSE)) print('MAE - Linear: %.2f, Ridge: %.2f, Lasso: %.2f' %(linear_MAE, ridge_MAE, lasso_MAE)) import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111) ax.plot(range(len(y_test)), y_test, '-', label="Original Y") ax.plot(range(len(y_test)), linear_y_hat, '-x', label="linear_y_hat") ax.plot(range(len(y_test)), ridge_y_hat, '-x', label="ridge_y_hat") ax.plot(range(len(y_test)), lasso_y_hat, '-x', label="lasso_y_hat") plt.legend(loc='upper right') plt.show()linear, lasso, ridge 3가지 방법으로 회귀를 시켜봤다. 그 결과

위와 같은 결과를 얻을 수 있었다. 일단 표본이 적고 테스트 케이스도 2개만 넣어줬던 터라 성능은 당연히 기대를 하지 않고 있었지만 lasso regression 에서 생각보다 괜찮은? 결과를 얻을 수 있었다.
표에서 결측치에 대한 처리를 해준 후 다시한번 돌려보겠다.
'finance' 카테고리의 다른 글
Finance - 2 (0) 2020.12.16